DeepSeek
2025-02-28
根据官方信息DeepSeek R1 可以看到提供多个版本,包括完整版(671B 参数)和蒸馏版(1.5B 到 70B 参数)。完整版性能强大,但需要极高的硬件配置;蒸馏版则更适合普通用户,硬件要求较低
DeepSeek-R1官方地址:https://github.com/deepseek-ai/DeepSeek-R1
· 完整版(671B):需要至少 350GB 显存/内存,适合专业服务器部署
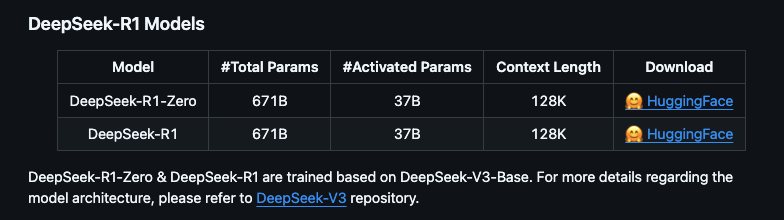
· 蒸馏版:基于开源模型(如 QWEN 和 LLAMA)微调,参数量从 1.5B 到 70B 不等,适合本地硬件部署。
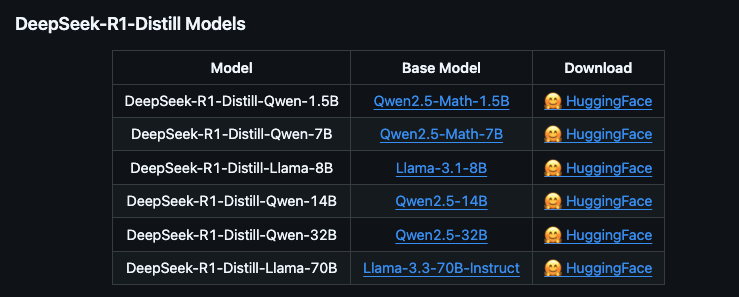
蒸馏版与完整版的区别
| 特性 | 蒸馏版 | 完整版 |
|---|---|---|
| 参数量 | 参数量较少(如1.5B、7B),性能接近完整版但略有下降。 | 参数量较大(如32B、70B),性能最强。 |
| 硬件需求 | 显存和内存需求较低,适合低配硬件。 | 显存和内存需求较高,需高端硬件支持。 |
| 适用场景 | 适合轻量级任务和资源有限的设备。 | 适合高精度任务和专业场景。 |
这里我们详细看下蒸馏版模型的特点
| 模型版本 | 参数量 | 特点 |
|---|---|---|
| deepseek-r1:1.5b | 1.5B | 轻量级模型,适合低配硬件,性能有限但运行速度快 |
| deepseek-r1:7b | 7B | 平衡型模型,适合大多数任务,性能较好且硬件需求适中。 |
| deepseek-r1:8b | 8B | 略高于7B 模型,性能稍强,适合需要更高精度的场景。 |
| deepseek-r1:14b | 14B | 高性能模型,适合复杂任务(如数学推理、代码生成),硬件需求较高。 |
| deepseek-r1:32b | 32B | 专业级模型,性能强大,适合研究和高精度任务,需高端硬件支持。 |
| deepseek-r1:70b | 70B | 顶级模型,性能最强,适合大规模计算和高复杂度任务,需专业级硬件支持。 |
进一步的模型细分还分为量化版
| 模型版本 | 参数量 | 特点 |
|---|---|---|
| deepseek-r1:1.5b-qwen-distill-q4_K_M | 1.5B | 轻量级模型,适合低配硬件,性能有限但运行速度快 |
| deepseek-r1:7b-qwen-distill-q4_K_M | 7B | 平衡型模型,适合大多数任务,性能较好且硬件需求适中。 |
| deepseek-r1:8b-llama-distill-q4_K_M | 8B | 略高于7B 模型,性能稍强,适合需要更高精度的场景。 |
| deepseek-r1:14b-qwen-distill-q4_K_M | 14B | 高性能模型,适合复杂任务(如数学推理、代码生成),硬件需求较高。 |
| deepseek-r1:32b-qwen-distill-q4_K_M | 32B | 专业级模型,性能强大,适合研究和高精度任务,需高端硬件支持。 |
| deepseek-r1:70b-llama-distill-q4_K_M | 70B | 顶级模型,性能最强,适合大规模计算和高复杂度任务,需专业级硬件支持。 |
蒸馏版与量化版
| 模型类型 | 特点 |
|---|---|
| 蒸馏版 | 基于大模型(如QWEN 或 LLAMA)微调,参数量减少但性能接近原版,适合低配硬件。 |
| 量化版 | 通过降低模型精度(如4-bit 量化)减少显存占用,适合资源有限的设备。 |
例如:
· deepseek-r1:7b-qwen-distill-q4_K_M:7B 模型的蒸馏+量化版本,显存需求从 5GB 降至 3GB。
· deepseek-r1:32b-qwen-distill-q4_K_M:32B 模型的蒸馏+量化版本,显存需求从 22GB 降至 16GB
我们正常本地部署使用蒸馏版就可以
- Windows 配置:
o 最低要求:NVIDIA GTX 1650 4GB 或 AMD RX 5500 4GB,16GB 内存,50GB 存储空间
o 推荐配置:NVIDIA RTX 3060 12GB 或 AMD RX 6700 10GB,32GB 内存,100GB NVMe SSD
o 高性能配置:NVIDIA RTX 3090 24GB 或 AMD RX 7900 XTX 24GB,64GB 内存,200GB NVMe SSD
- Linux 配置:
o 最低要求:NVIDIA GTX 1660 6GB 或 AMD RX 5500 4GB,16GB 内存,50GB 存储空间
o 推荐配置:NVIDIA RTX 3060 12GB 或 AMD RX 6700 10GB,32GB 内存,100GB NVMe SSD
o 高性能配置:NVIDIA A100 40GB 或 AMD MI250X 128GB,128GB 内存,200GB NVMe SSD
- Mac 配置:
o 最低要求:M2 MacBook Air(8GB 内存)
o 推荐配置:M2/M3 MacBook Pro(16GB 内存)
o 高性能配置:M2 Max/Ultra Mac Studio(64GB 内存)
可根据下表配置选择使用自己的模型
| 模型名称 | 参数量 | 大小 | VRAM (Approx.) | 推荐Mac 配置**** | 推荐Windows/Linux 配置**** |
|---|---|---|---|---|---|
| deepseek-r1:1.5b | 1.5B | 1.1 GB | ~2 GB | M2/M3 MacBook Air (8GB RAM+) | NVIDIA GTX 1650 4GB / AMD RX 5500 4GB (16GB RAM+) |
| deepseek-r1:7b | 7B | 4.7 GB | ~5 GB | M2/M3/M4 MacBook Pro (16GB RAM+) | NVIDIA RTX 3060 8GB / AMD RX 6600 8GB (16GB RAM+) |
| deepseek-r1:8b | 8B | 4.9 GB | ~6 GB | M2/M3/M4 MacBook Pro (16GB RAM+) | NVIDIA RTX 3060 Ti 8GB / AMD RX 6700 10GB (16GB RAM+) |
| deepseek-r1:14b | 14B | 9.0 GB | ~10 GB | M2/M3/M4 Pro MacBook Pro (32GB RAM+) | NVIDIA RTX 3080 10GB / AMD RX 6800 16GB (32GB RAM+) |
| deepseek-r1:32b | 32B | 20 GB | ~22 GB | M2 Max/Ultra Mac Studio | NVIDIA RTX 3090 24GB / AMD RX 7900 XTX 24GB (64GB RAM+) |
| deepseek-r1:70b | 70B | 43 GB | ~45 GB | M2 Ultra Mac Studio | NVIDIA A100 40GB / AMD MI250X 128GB (128GB RAM+) |
| deepseek-r1:1.5b-qwen-distill-q4_K_M | 1.5B | 1.1 GB | ~2 GB | M2/M3 MacBook Air (8GB RAM+) | NVIDIA GTX 1650 4GB / AMD RX 5500 4GB (16GB RAM+) |
| deepseek-r1:7b-qwen-distill-q4_K_M | 7B | 4.7 GB | ~5 GB | M2/M3/M4 MacBook Pro (16GB RAM+) | NVIDIA RTX 3060 8GB / AMD RX 6600 8GB (16GB RAM+) |
| deepseek-r1:8b-llama-distill-q4_K_M | 8B | 4.9 GB | ~6 GB | M2/M3/M4 MacBook Pro (16GB RAM+) | NVIDIA RTX 3060 Ti 8GB / AMD RX 6700 10GB (16GB RAM+) |
| deepseek-r1:14b-qwen-distill-q4_K_M | 14B | 9.0 GB | ~10 GB | M2/M3/M4 Pro MacBook Pro (32GB RAM+) | NVIDIA RTX 3080 10GB / AMD RX 6800 16GB (32GB RAM+) |
| deepseek-r1:32b-qwen-distill-q4_K_M | 32B | 20 GB | ~22 GB | M2 Max/Ultra Mac Studio | NVIDIA RTX 3090 24GB / AMD RX 7900 XTX 24GB (64GB RAM+) |
| deepseek-r1:70b-llama-distill-q4_K_M | 70B | 43 GB | ~45 GB | M2 Ultra Mac Studio | NVIDIA A100 40GB / AMD MI250X 128GB (128GB RAM+) |
我这里的演示的本地环境:
机器:M2/M3/M4 MacBook Pro (16GB RAM+)
模型:deepseek-r1:8b
简单说下在本地运行的好处
- 隐私:您的数据保存在本地的设备上,不会通过外部服务器
- 离线使用:下载模型后无需互联网连接
- 经济高效:无 API 成本或使用限制
- 低延迟:直接访问,无网络延迟
- 自定义:完全控制模型参数和设置
之后如果有Windows/Linux的场景需要在后续进行更新。
部署可以使用Ollama、LM Studio、Docker等进行部署
Ollama:
o 支持 Windows、Linux 和 Mac 系统,提供命令行和 Docker 部署方式
o 使用命令 ollama run deepseek-r1:7b 下载并运行模型
本地大模型管理框架,Ollama 让用户能够在本地环境中高效地部署和使用语言模型,而无需依赖云服务
LM Studio:
o 支持 Windows 和 Mac,提供可视化界面,适合新手用户
o 支持 CPU+GPU 混合推理,优化低配硬件性能
LM Studio 是一个桌面应用程序,它提供了一个用户友好的界面,允许用户轻松下载、加载和运行各种语言模型(如 LLaMA、GPT 等)
Docker:
o 支持 Linux 和 Windows,适合高级用户。
o 使用命令 docker run -d --gpus=all -p 11434:11434 --name ollama ollama/ollama 启动容器。
由于需要本地化部署语言模型的场景,对数据隐私和自定义或扩展语言模型功能有较高要求,我们这里使用Ollama来进行本地部署运行
如果只有集显也想试试玩,可以试试下载LM Studio软件,更适应新手,如果有需要后续更新
官方地址:https://ollama.com/